")


Mechmine = mechanical (data) mining – die Suche nach den nützlichen Informationen
Beim Data-Mining (DM) handelt es sich um Verfahren die in Daten nach relevanten Informationen suchen [1,2,3]. Als Daten verstehen wir hier digitalisierte und temporal hochaufgelöste Messwerte von Sensoren, welche auf Maschinen angebracht sind und deren Betriebsverhalten aufzeichnen. Dabei bedient man sich entweder statistischer Verfahren, mit welchen man in grossen Datenbeständen, die manuell nicht rechtzeitig bearbeitet werden könnten, nach Mustern ("patterns" [4]) und Eigenschaften sucht. Oder man verwendet Methoden die mittels Digitaler Signalverarbeitung (DSP) [5] und Kenntnissen aus Maschinenbau, Physik und Kinematik, die Daten auswerten. Mischverfahren sind auch möglich; Datenvorverarbeitung mit DSP im Frontend und Machine Learning (ML) im Backend hat sich als robust erwiesen [6]. Die verwendeten ML Methoden bzw. Algorithmen basieren z.B. auf Entscheidungsbäumen, Neuronalen Netzen (Artificial Neural Networks, ANN), Tiefen Neuronalen Netzen (Deep Neural Networks, DNN), Large Language Models (LLM), Support Vector Machines (SVM), Genetischen Algorithmen (GM), Diskriminant- oder Regressions-Analyse, oder regelbasierter Inferenz [1]. Der Data-Mining Prozess erfolgt stufenweise, in unserer Betrachtung, über die Musterauslese und Extraktion zur Klassifizierung gefolgt von einer Nachbearbeitung. Heute werden üblicherweise end-to-end Prozesse verwendet, nicht Stufen, aber diese benötigen mehr Trainingsdaten.
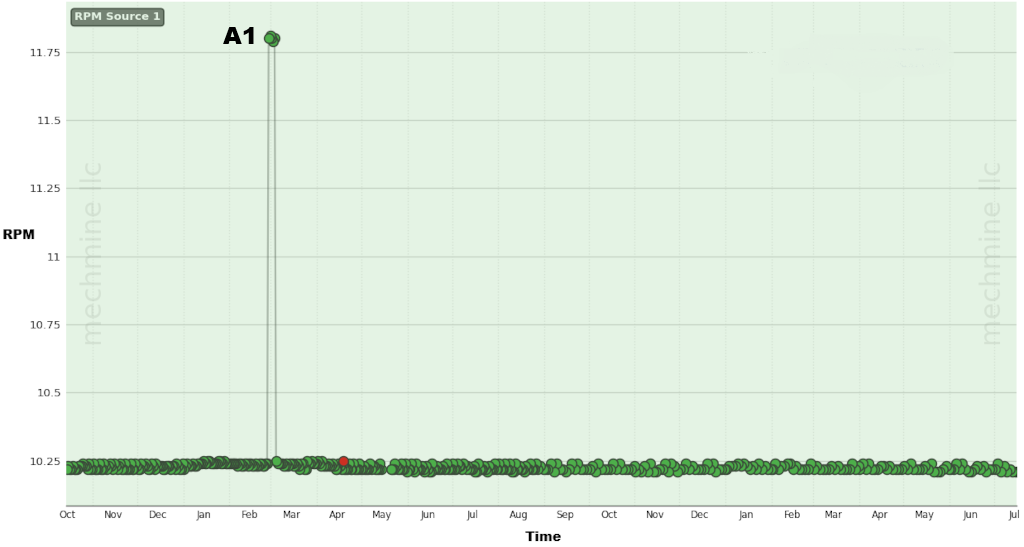
Ein Ziel der DM Verfahren ist, nützliche von wertlosen Informationen zu trennen, was an einem Beispiel erklärt werden soll. Das Bild unten links zeigt den Verlauf der Wellendrehzahl im U/min (RPM) über mehrere Monate und rechts sechs verschiedene Schwingungspegel (Vibrationlevel) eines Rührwerks. Die nominale Drehzahl ist 10.25 RPM aber plötzlich springt diese auf 11.75 RPM (+15%), weil z. B. das Mischgut dies erfordert. Diese Drehzahländerung A1 hat mehrere Schwingungspegel tangiert, siehe B1 (Kurven orange, grün, braun) im Bild rechts. Aber die Anomalien B2 hatten beispielsweise keine Drehzahländerung als Ursache.
Eine robuste Predictive Maintenance (PM) Methode müsste also:
- im Fall A1/B1: immun gegenüber betriebsbedingten Anomalien sein (wenn wie hier die Drehzahl Ursache ist),
- im Fall A1/B1: einen Alarm auslösen wenn diese Anomalie zu einem Schaden führt,
- im Fall B2: einen Alarm auslösen wenn dieser Anomalie beispielsweise ein Schadensfall zu Grunde liegt.
 |
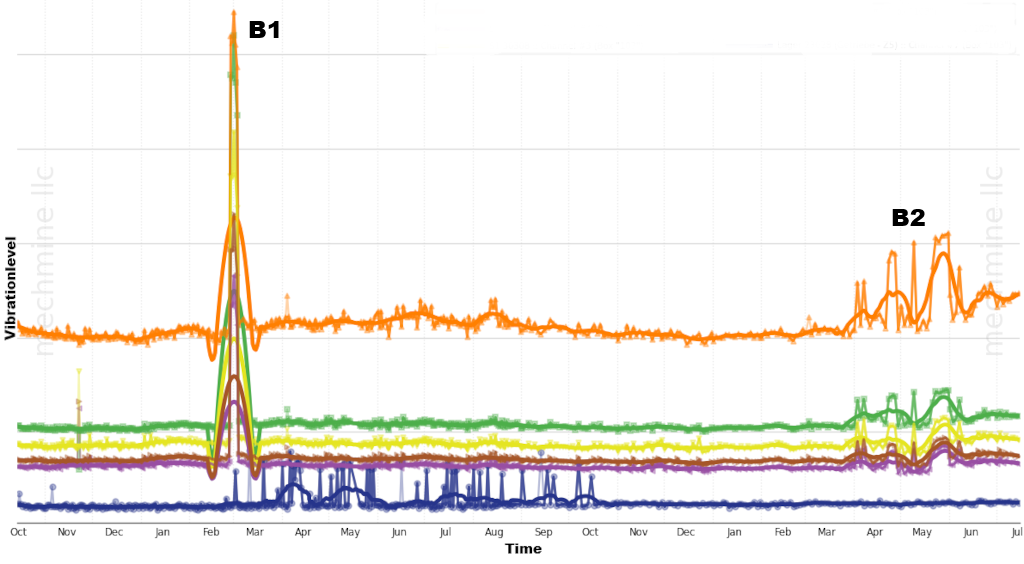 |
Wie die drei Fälle oben aufzeigen, könnte man den RPM Wert als Indikator für einen Falschalarm verwenden. Ein auf Statistik beruhendes PM Verfahren könnte mittels Trainingsdaten, die solche Muster auch beinhalten, so konditioniert worden sein, dass es der Anomalie B1 eine geringe Wahrscheinlichkeit für die Verursachung eines Schadens zuweist. Beim Betrachten der Bilder oben kommt die menschliche Intelligenz zum Schluss, dass die Schwingungspegel nach B1 bzw. A1 wieder auf den alten Wert, vor B1, zurückgehen, und B1 somit eine gutartige Anomalie sein müsste. Diese Aussage ist aber nur nach dem Heranziehen mehreren Datensätzen nach A1 möglich, wenn die Pegelwerte wieder "wie vorher" sind. Wir folgern: ein auf Statistik beruhendes PM Verfahren braucht passende Trainingsdaten zur Urteilsfindung, ein alternatives PM Verfahren könnte mittels Historie im Datenspeicher (Gedächtnis) zu einem Urteil kommen ob B1 eine gutartige oder bösartige Anomalie ist. Die eine Methode kann sofort urteilen, die andere verzögert, die Erstere braucht vorher Trainingsdaten, die Letztere keine. Mechmine verwendet eine Methode die keine Trainingsdaten benötigt und sofort ein Urteil abgeben kann [6].
Als Nächstes sollen drei PM Verfahrensaspekte vertieft diskutiert werden: Datenverarbeitung, Modellierung und die weit verbreitete Anomaliedetektion.
Generell kann man die Datenverarbeitung auf zwei Arten umsetzen, man verarbeitet Datenblöcke mit fixer Anzahl von Samples (digitalisierte Sensorwerte) oder den kontinuierlichen Datenstrom (Datastream) von Samples. Datenblöcke von der Länge einer 2er-Potenz werden z. B. für eine FFT verwendet [5], und die Länge beschreibt dann auch die physikalische Frequenzauflösung. Das kontinuierliche Verarbeiten von Samples verlangt nach einer SW Architektur welche den Fluss der Messwerte ermöglicht. Das Bild unten illustriert konzeptionell den Unterschied beider Prozesse.
Im oberen Anwendungsbeispiel wird zuerst aus Trainingsdaten eine statistische Verteilung berechnet, blaues Histogramm, die "Reference pdf" (probability density distribution [7]). Dann im aktiven Betrieb (d.h. Maschinenüberwachung) wird block-by-block von jedem Datenblock eine pdf erstellt und mit der Reference pdf verglichen. Daraus wird eine Distanz Δ berechnet, welche die Abweichung der beiden Verteilungen beschreibt: blaues Histogramm (Referenz, z. B. neue Maschine) versus grüne Kurve (aktuelles Maschinenverhalten). Am Schluss wird der Wert der Distanz beurteilt (Assessment). Der Distanzwert kann numerisch oder grafisch dargestellt werden und je nach voreingestelltem Grenzwert eine Warnung oder Alarm auslösen. Die oben beschriebene Funktionsweise erklärt prinzipiell auch eine mögliche Realisierung eines Anomalie- bzw. Ausreisser Detektors.
Eine Datastream Datenverarbeitung kann man sich wie ein digitales Filer vorstellen [5], links fliessen die Daten in den Analyseblock hinein und rechts kommen sie verarbeitet heraus, und werden dann beurteilt (Assessment). Ein paar Optionen für Analyseverfahren sind unten auch aufgeführt [1,3,5]. Die Analyse und Beurteilung müssen aufeinander abgestimmt sein, was die Komplexität nicht vereinfacht!
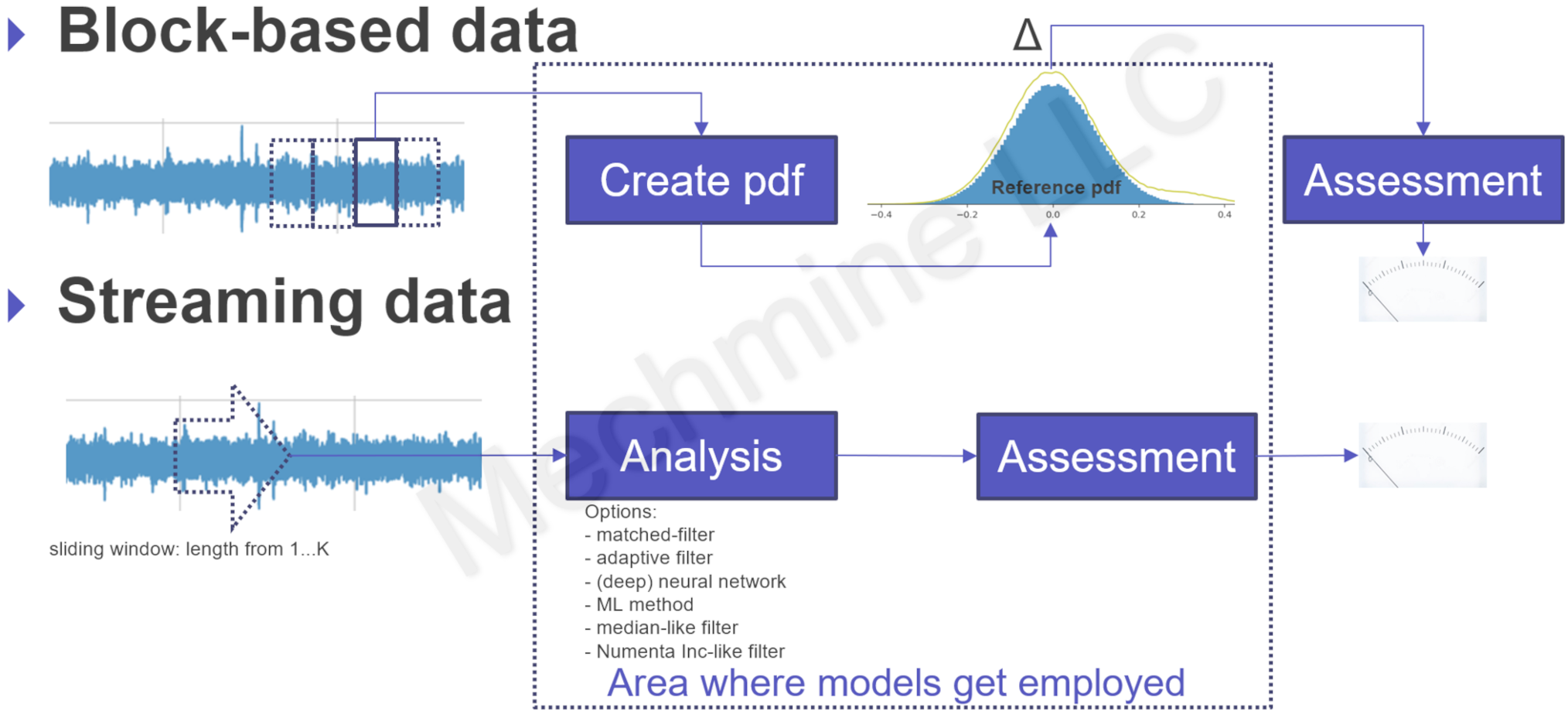 |
Im Bild oben erkennt man, wo man Modelle einsetzen kann. Mit Modell werden hier trainierte Übertragungsfunktionen bezeichnet; während des Trainings werden z. B. die Neuronengewichte in Netzwerken (ANN, DNN), die Entscheidungskriterien bei Bäumen oder die Filterkoeffizienten bei adaptiven Filtern optimiert. Das nächste Bild erklärt an zwei Beispielen wie solche Modelle in der Praxis trainiert werden könnten.
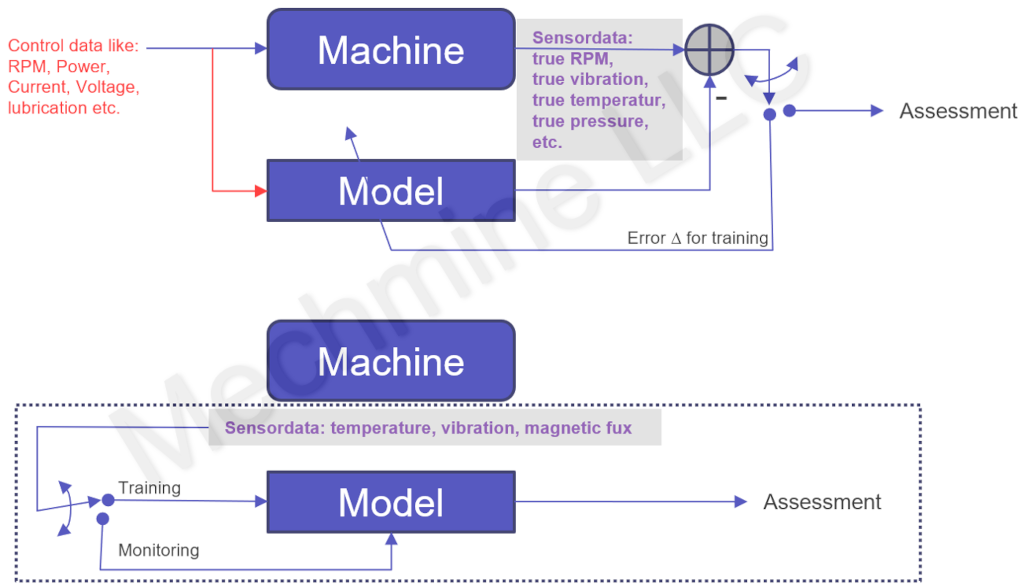
Das Bild unten zeigt oben den Normalfall in einer Fabrik, wo eine Maschine mit Steuerungsdaten (control data) gesteuert wird. Links gibt der Operateur Drehzahl oder Leistung vor (roter Text), die Sensorik überwacht die Maschine und liefert Sensordaten wie RPM, Leistung oder Vibrationspegel zurück (violetter Text), welche dann der Steuerung mitteilen, ob Drehzahl oder Leistung erreicht sind, sonst regelt die Steuerung nach. Parallel dazu wird, typ. auf einem Rechner, ein Modell (Blackbox) trainiert, welches die Maschine bzw. deren Eigenschaften/Verhalten erlernen soll. Dazu erhält das Modell auch die Steuerungsdaten (rot) und die Sensordaten (violett), plus einen Fehlerwert Δ während der Trainingsphase. Dieses Konzept kennt man von den adaptiven Filtern [5], aber hier geht es nicht um die Filterung (Entzerrung) von Telefongesprächen oder Mobilfunkdaten, sondern um die Abbildung des Maschinencharakters in Software, z. B. mit einem digitalen Zwilling.
Im Bild unten zeigt das untere Blockdiagramm schematisch einen IoT-Sensor, kleiner batteriebetriebener Funksensor mit integrierter Sensorik, ideal für PM Anwendungen. Der IoT-Sensor sitzt auf einer Maschine, liefert Sensordaten wie Temperatur, Vibrationspegel oder Magnetflusswerte. Am IoT-Sensor kann man oftmals zwischen Trainingsmodus und Überwachung umschalten. Im Trainingsmodus werden während einer vorgegebenen Zeit die Sensordaten begutachtet, d.h. deren statistische Eigenschaften ausgewertet. Beispielsweise könnte eine "Reference pdf" erstellt und abgespeichert werden. Im Aktivbetrieb (Monitoring) werden dann die Sensordaten mit den Referenzdaten verglichen und beurteilt, und ggf. ein Alarm ausgelöst.
 |
Je mehr Freiheitsgrade eine Maschine in der Produktion hat, d.h. variable Drehzahl, variable Leistung, allerlei verarbeitete Medien/Dichten/Viskositäten (wie bei Pumpen), umso schwieriger wird es, mit einmaligem Training dieses ganze Potpourri an Betriebsmodi mit einem einzigen Referenzdatensatz abzudecken. Regelmässige Falschalarme sind dann beim IoT-Sensor fast unumgänglich. Der beschriebene Umstand erklärt, dass selten genügend Trainingsdaten vorliegen die alle Betriebsmodi charakterisieren, um ein Modell wie ein ANN zu trainieren. Des Weiteren muss man bedenken, dass die Grösse (Komplexität) eines Modells auch von der Vielseitigkeit der Daten, der Variabilität, abhängt.
Der Energieverbrauch bzw. die Batteriekapazität diktiert die maximale Modellkomplexität (wie Anzahl Schichten und Neuronen bei ANN/DNN) bei batteriebetrieben IoT-Sensoren. Deshalb verwenden die eher günstigen IoT-Sensor in der Regel sog. 1-Klassen Klassifizierungsmodelle. Diese eine Klasse beschreibt (statistisch) nur ein Maschinenverhalten, idealerweise jenes einer neuen oder frisch revidierten Maschine. Wendet man dieses Verfahren für eine alte Maschine an, dann trainiert man womöglich das Modell mit Daten welche einen Maschinenschaden beinhalten. Das nächste Bild illustriert schematisch, wie ein 1-Klassen Klassifizierer in einem IoT-Funksensor funktioniert. Links kommen die Daten der im IoT-Sensor integrierten Messsensoren an. Während der Trainingsphase wird eine Referenz erstellt, diese 1-Klasse, und in einer Datenbank abgelegt. Beim Wiedereinschalten des IoT-Sensors wird die Referenz aus der Datenbank hervorgeholt, ein erneutes Training entfällt. Im Normalbetrieb sehen die Sensordaten wie jene während des Trainings aus, d.h. sie kommen alle im grauen Kreis zu liegen, und der rechts ausgegebene Anomaliewert ist 0. Wenn dann plötzlich ein Ausreisser vorliegt, der vielleicht ausserhalb des grünen Kreises zu liegen kommt, dann wird ein Anomaliewert von 2 ausgegeben, ev. leuchtet eine orange LED auf oder ein Alarm (via Funk) wird abgesetzt. Das Vorhandensein einer Datenback ermöglicht das Abspeichern von Modellen für verschiedene Betriebsmodi. PM Sensoren mit integriertem 1-Klassen Klassifizierer eignen sich typischerweise eher für Maschinen mit nur einem Betriebsmodus, aber auch hier besteht immer noch ein Risiko erhöhter false-positives Werte.
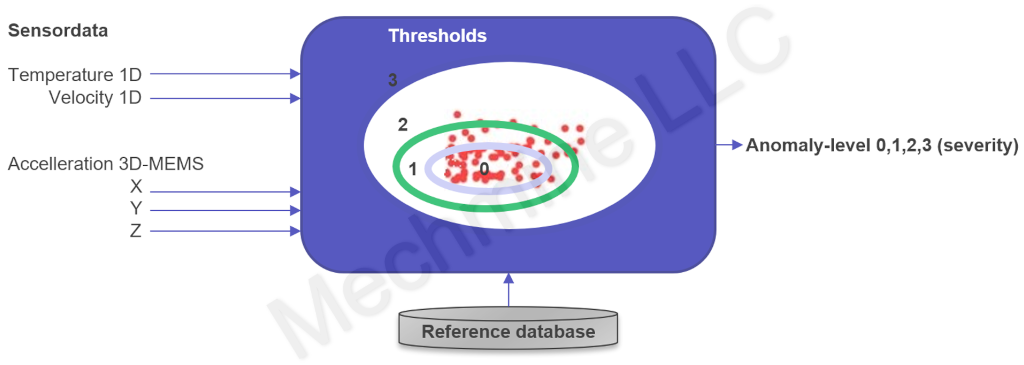 |
Der allereinfachste Ausreisserdetektor vergleicht einen Messwert (wie Spannungswert) mit Grenzwerten wie beispielsweise ±3σ oder ±9σ (Standardabweichung σ), und schlägt Alarm wenn dieser Schwellwert überschritten ist. Bei normalverteilten Werten kann hier die Anzahl Alarme, oder Falschalarme, theoretisch berechnet werden. In der Praxis sind die Schwingungsdaten oftmals nicht normalverteilt sondern folgen komplexeren Verteilungen, was erhöhte Falschalarmraten zur Folge hat.
Zusammenfassung
Die Qualität und Performanz eines Data-Mining Systems hängt massgeblich auch von der Vorverarbeitung der Daten ab. Informationen die zuerst bei der Datenakquise (Sensorik) oder diesem Vorgang verloren gehen, kann der beste Algorithmus dann nicht mehr aus den Daten extrahieren. Die Datenvorverarbeitung erachten wir als essentiell [3]. Traditionelle Methoden basieren auf der Fast Fourier Transform (FFT) oder Principal Component Analysis (PCA) [1,4,5,7]. Durch die parallele Anwendung mehrerer Verfahren und einer intelligenten Auswahlstatistik, kann die Performanz eines Data-Mining Systems massiv verbessert werden.
Quellen
[1] R. Nisbet et al., "Statistical analysis & data mining applications", Academic Press, 2009.
[2] C. Manning, "Introduction to information retrieval", Cambridge University Press, 2008.
[3] A. Gelman et al., "Bayesian data analysis", CRC Press, 2014.
[4] R. Duda et al., "Pattern classification", Wiley, 2001.
[5] E. Ifeachor, B. Jervis, "Digital signal processing", Addison-Wesley, 1993.
[6] Text "Laufzeitverlängerung Dank vorausschauender Instandhaltung"
[7] W. Press et al., "Numerical recipes in C", Cambridge University Press, 1992.
